This is going to be a highly opinionated blog post. I think AWS is great and use it daily, but their implementation of IAM is unnecessarily complicated.
If you can’t tolerate critics, don’t do anything new or interesting.
Jeff Bezos
Let’s get started.
The policy evaluation logic reads like a James Joyce novel:
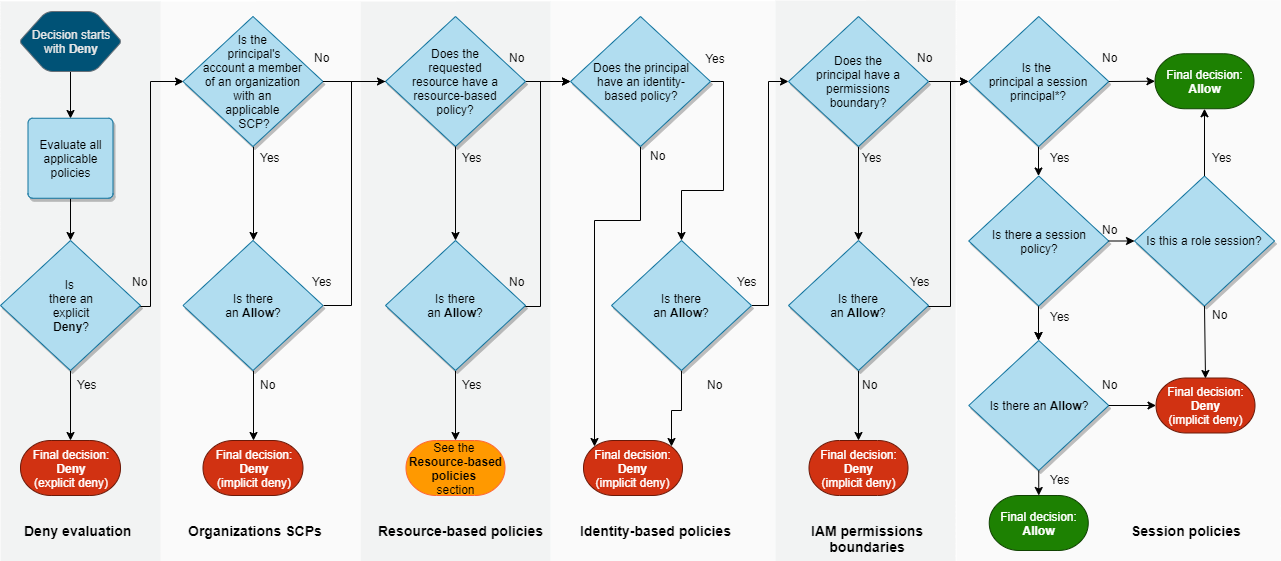
Does it need to be this complex?

Because AWS is doubling down on a flawed Organizational model.
A bit of history
We need to go back to the history books Wayback Machine to understand why things are so. First came the services (this rant comes to mind) - S3, SQS and EC2. At that time, “Amazon Web Services” was hardly a “cloud provider”, but rather a few disjointed building blocks. It took many years for the current IAM service to be released. Back then it fit the purpose, namely managing authentication and authorization in a single AWS account.
The introduction of IAM came with 2 types of principals:
- Users, representing human actors
- Groups, a container for users allowing for “role based access control”
This new service also included the concept of policies, which allowed defining what a principal could do (identity-based policies) as well as what a resource allowed for (resource-based policies).
A few years later, the “roles for EC2 instances” feature was released:
Today we are introducing AWS Identity and Access management (IAM) roles for EC2 instances, a new feature that makes it even easier for you to securely access AWS service APIs from your EC2 instances. You can create an IAM role, assign it a set of permissions, launch EC2 instances with the IAM role, and then AWS access keys with the specified permissions are automatically made available on those EC2 instances.
This made sense - no more need to hardcode an IAM users’ API keys in your applications and workloads!
This now meant we had a third type of principal:
- Roles, an “identity” that an instance, workload or application impersonates to gain API permissions
The implementation of this new principal required the ability to provide EC2 instances with temporary credentials. This was initially only available via the EC2 Instance Metadata Service, but was later generalized by the AWS Security Token Service (STS) service. With this new service, you could now easily get temporary credentials for any role. Neat!
As adoption of the cloud grew, organizations started to identify the need for using multiple AWS accounts. This posed a serious problem, because AWS’ architecture didn’t easily support managing access and permissions for multi-account scenarios. This is where things started going sideways. Instead of refactoring the architecture, AWS did what AWS does best - it built a new service.
I can envision a meeting in an unmarked office building, downtown Seattle. A team is hashing out the details of the new “Organizations” service they’ve been tasked to build, allowing management of multiple accounts by a single entity. They come to the topic of AWS account access:
- Product Manager: How are people going to authenticate to all these accounts?
- Engineer: Why don’t we just use roles?
- Product Manager: Roles? I thought those were just for EC2?
- Engineer: Well you know, IAM roles can already be
impersonatedassumed by a principal in another account so… there’s really nothing we need to add? Let’s just use this mechanism to allow access to an Organization’s sub-accounts and call it a day. - Product Manager: But won’t that be confusing? Since you know, roles are for “instances, workloads or applications?”
- Engineer: Hey man, we can either do it this way or take 100x more time and re-architect the whole thing.
- Product Manager: Sold!
And just like that, AWS Organizations as we know it was born.
How does organizations implement sub-account access via roles? Well, you create permission sets in SSO, which are essentially IAM policies. When you “attach” a permission set to an SSO user or group in a given sub-account, Organizations will automagically create a role in that account with the permissions defined in the set. Once the user (or member of the group) authenticates to SSO, they’re presented with the accounts they can access by assuming (via SSO, not directly) the role created by Organizations.
A consequence of this change was to further remove any coherent meaning for the term “role”, as it didn’t strictly refer to:
- programmatic identities, since any principal (users, groups & roles) can potentially assume any role and Organizations relies on role assumption for sub-account access
- federated identities (as in IdP/SSO), since workloads as well as AWS services can assume a role
- Role Based Access Control (RBAC), which is a standard term in the industry (and is the traditional authorization model used in IAM1)
- To be fair, this was an issue from the start
So what is an IAM role then? Simply put, it’s a principal (i.e. an identity) with no long-lived credentials, that can be impersonated for arbitrary purposes.
Looking around
All right, so we’ve established the timeline for AWS IAM’s progress, and asserted that AWS Organizations is when things went wrong. Could it have been any other way?
I think it would have, if AWS hadn’t treated “multi-account management” as “just another service”. So why did they?
No problem can be solved from the same level of consciousness that created it.
Albert Einstein
This is where Google Cloud Platform, Google’s (not-yet-canned 😅) cloud provider comes into play. GCP’s infancy was similar to AWS’ in that the initial offering was a single service, App Engine. But Google had two advantages over Amazon:
- By being released later (GA in 2011, the same year AWS launched IAM), they surely benefited from the ability to learn from AWS’ achievements and mistakes.
- They even copied things like the super unsafe and not really useful
allAuthenticatedUsersbucket ACL, which AWS highly recommends against (and have hidden away from the web console).
- They even copied things like the super unsafe and not really useful
- Google already had the G Suite identity provider (now Google Workspace), removing the need for a new authentication mechanism.
The result? GCP’s Resource Hierarchy:
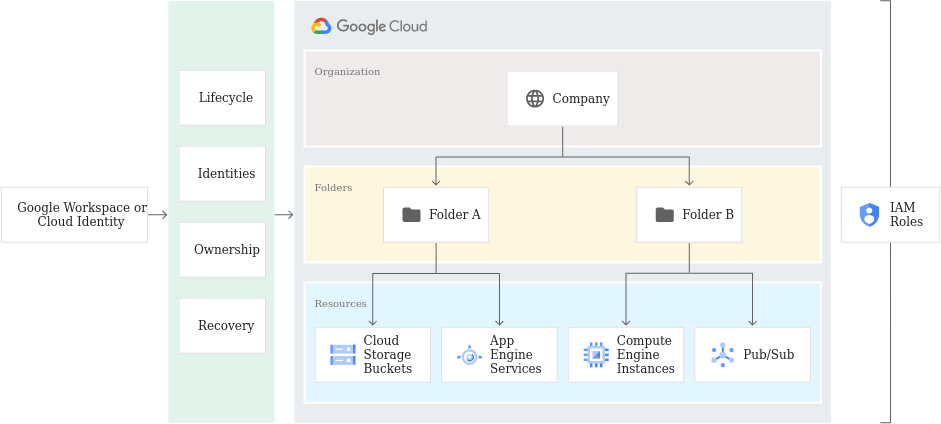
The purpose of the Google Cloud resource hierarchy is two-fold:
- Provide a hierarchy of ownership, which binds the lifecycle of a resource to its immediate parent in the hierarchy.
- Provide attach points and inheritance for access control and organization policies.
Metaphorically speaking, the Google Cloud resource hierarchy resembles the file system found in traditional operating systems as a way of organizing and managing entities hierarchically. Generally, each resource has exactly one parent. This hierarchical organization of resources enables you to set access control policies and configuration settings on a parent resource, and the policies and Identity and Access Management (IAM) settings are inherited by the child resources.
The brilliant thing with this implementation is that it ties permissions (e.g. read access to storage buckets) to their location (e.g. the buckets in the production project), which provides context. In AWS, policies/permissions exists within the whole AWS account they belong to. You need to add specific Conditions , or to define the Resources to which the permissions apply to scope down access. In practice, this is rarely implemented comprehensively and leads to significant complexity. And that’s if you’re creating the permissions yourself - AWS-managed permissions will apply to everything in that account.
Thanks to its ease of use, GCP’s resource hierarchy also fosters better isolation of environments. I can’t tell you how many times I’ve seen large, mature organizations have their production, staging and development environments in the same AWS account (often the Organization’s management account, which is excluded from Security Control Policies). Compounded with the above, the end result is an environment rich in privilege escalation and lateral movement vectors.
What about the process required for a GCP user to access the different levels of the hierarchy? Easy - if a user has permissions granted in that project (it’s really if a user is assigned a role in that project, but we’re already confused enough with the terminology), then they can use those permissions. No need for additional principals, role assumption chains or overly complex edge cases that almost no one understands.
And when it comes to security, simpler often leads to safer.
GCP is not a panacea
GCP IAM is definitely not perfect. When auditing GCP organizations we often find issues such as:
- Too many permissions granted at the Organizational node, which are then inherited by the rest of the resource tree
- Lack of a defined resource hierarchy, which limits assigning roles in a manner that adheres to the principle of least privilege
- An overuse of basic roles, granting too many permissions
The difference is that these are sub-par configurations, which are easier to fix as they are primarily caused by not making the most of GCP’s resource hierarchy, rather than the architecture forcing complexity and misconfigurations.
To remediate the above:
- Grant permissions closer to where they are needed
- Restructure the resource hierarchy, which is easy enough as folders and projects can be moved
- Use predefined or custom roles
What I’d like to see
Here are some changes that would help improve what I’ve outline above.
Stop saying “role”
It may be too late, but the term is a misnomer. IAM roles aren’t roles, they are service identities. Or service principals. Or service accounts. Calling programmatic identities “roles” is incorrect and confusing. Roles relate to tasks and the permissions required to complete them - they are not an identity, they relate to an identity.
While we’re at it, saying “assuming” a role makes no sense. It’s impersonating, or simply getting temporary credentials for the identity.
Make users first class citizens
If we can’t rename roles, can we at least stop using them for everything? Couldn’t identities created in AWS SSO simply exist in the Organization’s sub-accounts?
Something like this:
- Current: Attaching a permission set creates a role in the sub-account that the SSO user can assume to get access to said sub-account.
- Proposed: Attaching a permission set creates a representation of the SSO user in the sub-account. The SSO user can then get temporary tokens (i.e. create a session) in that account (just create a new identifier), which has the permissions granted by the permission set.
No more single accounts, Organizations are the default
Take a break from being “first” and replicate the competition’s wins for a change. Follow the same model GCP, Azure and even OCI implement and make the creation of an Organization the default when you sign up for AWS.

Is this a significant task? Sure! Akin to retiring EC2-Classic.
This would also solve an issue we see constantly, where a company started off with a single account where they deployed all their infrastructure. At some point they figure they need more accounts so they set up Organizations with this account as their management account. Then they realize they need to decouple the management account from the infrastructure, e.g. because SCPs don’t apply to that account. Chaos ensues.
Closing thoughts
I hope this rant is useful to someone, if only to highlight that it’s okay to be critical of something most of the industry is using, and that things can always be improved upon.
Many thanks to Patrick Farwick for his insightful comments and feedback.